Top-conf paper digest — week of June 16-19, 2026
Ten arXiv papers from the June 16-19 recent batches, grouped by LLM/code, agents, vision, ML methods, and RL security. This issue highlights ICLR/ICML/CVPR-tagged work plus one clearly labeled NeurIPS 2026 submission, with method notes, key results, resource links, and peer-review status for each paper.

Research Brief
This issue selects 10 arXiv papers first submitted or revised from June 16 to June 18, and surfaced in the June 16-19 arXiv recent batches. I prioritized main-conference, oral, spotlight, findings, or explicitly top-conference-tagged records; workshop-only entries and already-covered June 15 items were left out.
| Area | Paper | Venue status | Why it made the cut |
|---|---|---|---|
| LLM / code | Multi-LCB | ICLR 2026 | Extends LiveCodeBench from Python to 12 programming languages and evaluates 24 LLMs, directly testing whether coding models overfit to Python. 1 |
| Agents | ToolPro | ICML 2026 | Turns multi-step web-service use into executable tool programs, reporting up to 53.4% lower latency and 96.1% lower client-side traffic. 2 |
| Agents / video | OmniAgent | ICML 2026 | Recasts long-video understanding as active perception, with a 7B agent beating Qwen2.5-VL-72B on LVBench, 50.5% versus 47.3%. 3 |
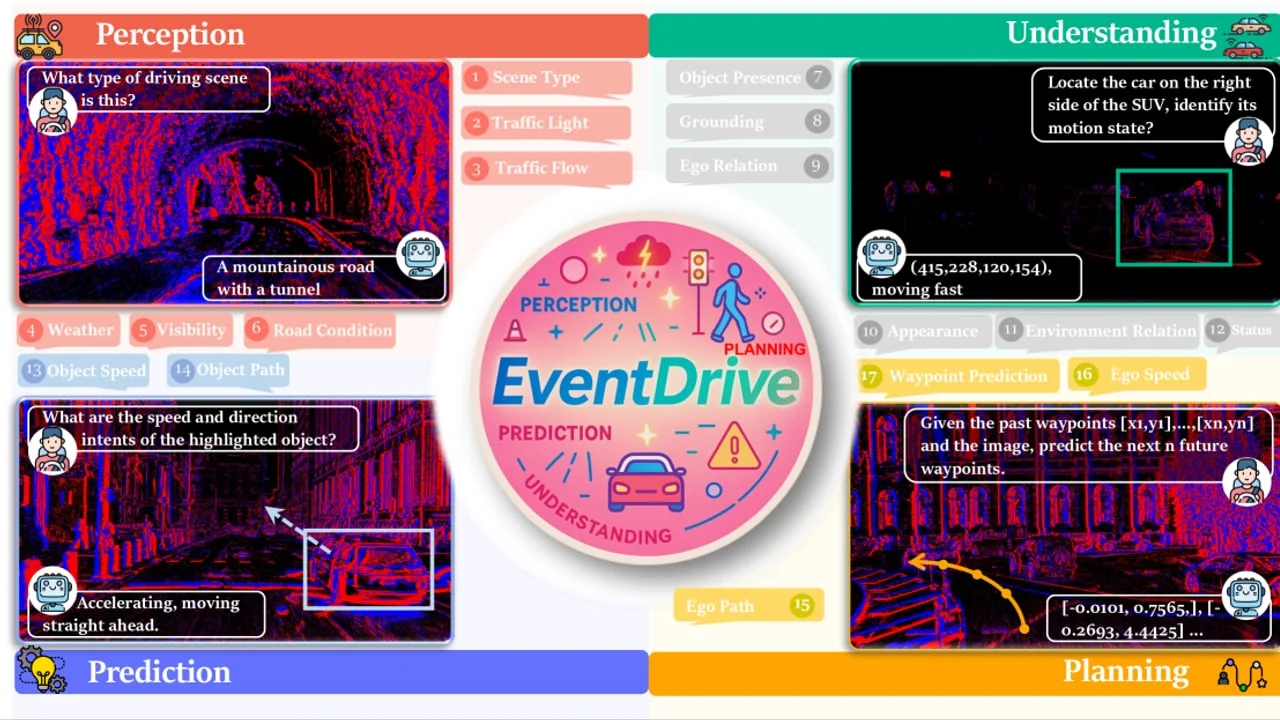
| Vision / driving | EventDrive | CVPR 2026-tagged preprint | Builds a 471k-sample event-frame-language driving benchmark across 17 subtasks from perception to planning. 4 |
| Vision / generation | UniAR | ICML 2026 | Uses one shared visual tokenizer for understanding and generation, with 32× visual sequence compression in autoregressive prediction. 5 |
| Vision / medical | PRDiT | ICLR 2026 | Generates 3D CT volumes directly at voxel level with a local denoiser plus global residual diffusion transformer. 6 |
| Vision / restoration | LSM | CVPR 2026 Findings | Applies linear recurrent units to super-resolution with semantic modulation and released code/models. 7 |
| ML methods | Calibrated MoE | ICML 2026 | Shows why expert-level calibration can fail for soft-routed MoEs under routing-induced distribution shift. 8 |
| ML methods | Smooth SMoE | ICML 2026 Spotlight | Gives geometric and stochastic bounds for top-k MoE discontinuities and proposes a smoothing mechanism. 9 |
| RL / security | SWAAP | NeurIPS 2026 submission | Targets learned world-model adaptation with stealth-constrained data poisoning across continuous-control tasks. 10 |
LLM and agent systems
Multi-LCB: extending LiveCodeBench to multiple programming languages
- Area tag: LLM evaluation / code generation.
- arXiv: 2606.20517; first submitted June 18. 1
- Authors / institutions: Maria Ivanova, Pavel Zadorozhny, Rodion Levichev, Ivan Petrov, Pavel Adamenko, Ivan Lopatin, Alexey Kutalev, and Dmitrii Babaev; the HTML lists GigaCode and Yandex School of Data Analysis / Applied AI Institute. 11
- Peer-review status: ICLR 2026, as stated in the arXiv comments field. 1
- Core problem: LiveCodeBench is contamination-aware but Python-only, so it cannot tell whether a model’s coding skill transfers to C++, Java, JavaScript, Rust, or other practical languages. 11
- Method highlights: Multi-LCB converts LiveCodeBench tasks into 12 programming languages while keeping the original benchmark format, release-date filtering, and update path. 11
- Results / takeaway: The paper evaluates 24 instruction and reasoning LLMs and reports Python overfitting, language-specific contamination, and large multilingual performance disparities; the practical takeaway is that Python pass@1 should not be treated as a proxy for general software-engineering competence. 1
- Code / resources: github.com/Multi-LCB/Multi-LCB. 11
Loading content card…
ToolPro: executable tool programs for agentic web services
- Area tag: Agents / tool use / service interface.
- arXiv: 2606.19992; first submitted June 18. 2
- Authors / institutions: Mugeng Liu, Shuoqi Li, Yixuan Zhang, and Yun Ma; the fetched arXiv HTML does not expose affiliations. 12
- Peer-review status: Accepted by ICML 2026. 2
- Core problem: Static API endpoints force agents to externalize loops, conditionals, retries, and joins as brittle step-by-step calls. 12
- Method highlights: ToolPro represents an agent’s intent as an executable program with explicit read/write effects, constraint-guided construction, effect-aware replay for exactly-once write semantics, and a policy that decides when consolidation beats stepwise calling. 2
- Results / takeaway: In MCP-style services with WebAssembly sandboxing, ToolPro reports up to 53.4% lower end-to-end latency and up to 96.1% lower client-side traffic; the strongest gains appear when workflows are longer or network latency is higher. 2
- Code / resources: github.com/morgen52/toolpro_icml26. 12
Loading content card…
OmniAgent: active perception for long-video omni-modal reasoning
- Area tag: Agents / multimodal video / long-context reasoning.
- arXiv: 2606.19341; first submitted June 17. 3
- Authors / institutions: Zhenghao Xing, Ruiyang Xu, Yuxuan Wang, Jinzheng He, Ziyang Ma, Qize Yang, Yunfei Chu, Jin Xu, Junyang Lin, Chi-Wing Fu, and Pheng-Ann Heng; the HTML lists The Chinese University of Hong Kong, Shanghai Jiao Tong University, Qwen Team / Alibaba Group, and Nanyang Technological University. 13
- Peer-review status: Accepted at ICML 2026. 3
- Core problem: Passive video models process frames broadly, so cost grows with video duration even when a question needs only a few moments. 3
- Method highlights: OmniAgent treats video understanding as a POMDP-style observation-thought-action loop, maintains persistent textual memory, and trains with agentic SFT plus TAURA, a turn-aware reinforcement objective. 13
- Results / takeaway: The 7B model reports 67.8% on VideoMME, 71.1% on MLVU, and 50.5% on LVBench; on LVBench it outperforms the 10× larger Qwen2.5-VL-72B while using 73% fewer frames. 13
- Code / resources: github.com/harryhsing/omniagent, plus SFT and RL checkpoints on Hugging Face. 3
Loading content card…
Vision and multimodal generation
EventDrive: event cameras for vision-language driving intelligence
- Area tag: Vision-language driving / event sensing.
- arXiv: 2606.18242; first submitted June 16. 4
- Authors / institutions: Dongyue Lu, Rong Li, Ao Liang, Lingdong Kong, Wei Yin, Lai Xing Ng, Benoit R. Cottereau, Camille Simon Chane, and Wei Tsang Ooi; affiliations include NUS, HKUST(GZ), CNRS@CREATE, Horizon Robotics, A*STAR I2R, IPAL / CNRS, University Toulouse / CNRS / CerCo, and ETIS / CY Cergy Paris University / ENSEA / CNRS. 14
- Peer-review status: The arXiv comments field tags CVPR 2026, but the abstract page does not explicitly state accepted / oral / spotlight, so I mark it as a CVPR 2026-tagged preprint. 4
- Core problem: Event cameras offer microsecond latency and high dynamic range, but most event-aware vision-language work stops at generic perception rather than driving decisions. 4
- Method highlights: EventDrive unifies event streams, RGB frames, and language supervision across perception, understanding, prediction, and planning; EventDrive-VLM adds a multi-horizon event pyramid and temporal-horizon MoE fusion. 4
- Results / takeaway: The benchmark contains 471k event-frame-language samples and 17 subtasks, making it useful for testing whether temporal event cues improve motion awareness and planning rather than just low-level detection. 14
- Resources: Project page and dataset links are exposed in the paper HTML, including a Hugging Face dataset link. 14
UniAR: one visual tokenizer for understanding and generation
- Area tag: Multimodal generation / unified autoregressive modeling.
- arXiv: 2606.18249; first submitted June 16 and revised June 17. 5
- Authors / institutions: Wujian Peng, Lingchen Meng, Yuxuan Cai, Xianwei Zhuang, Yuhuan Yang, Rongyao Fang, Chenfei Wu, Junyang Lin, Zuxuan Wu, and Shuai Bai; the HTML lists Fudan University’s Institute of Trustworthy Embodied AI, Shanghai Innovation Institute, and Qwen Team / Alibaba Inc. 15
- Peer-review status: ICML 2026, as stated in the arXiv comments field. 5
- Core problem: Unified multimodal models often use separate visual tokenizers for understanding and generation, which breaks the idea that a model can interpret its own generated visual tokens in the same context. 5
- Method highlights: UniAR uses multi-level feature fusion, lookup-free bitwise quantization, parallel bitwise prediction, and a diffusion decoder that reconstructs images from predicted visual tokens. 5
- Results / takeaway: The paper reports 32× visual compression for autoregressive prediction and says a 1024×1024 image requires predicting only 256 visual tokens when upsampling is used; the design is a strong signal that visual-token efficiency is becoming central to unified generation models. 15
- Resources: sharelab-sii.github.io/uniar-web. 5
PRDiT: voxel-level residual diffusion for 3D CT volumes
- Area tag: Medical vision / 3D generative modeling.
- arXiv: 2606.20112; first submitted June 18. 6
- Authors / institutions: Zhenkai Zhang, Markus Hiller, Krista A. Ehinger, and Tom Drummond; the HTML lists the School of Computing and Information Systems at The University of Melbourne. 16
- Peer-review status: Accepted at ICLR 2026. 6
- Core problem: High-resolution 3D CT synthesis is expensive because voxel feature maps grow cubically with resolution and latent autoencoders can lose anatomical detail. 16
- Method highlights: PRDiT splits generation into a local MLP denoiser for overlapping 3D patches and a memory-efficient global residual diffusion transformer for high-frequency structure. 6
- Results / takeaway: On LIDC-IDRI and RAD-ChestCT, the abstract reports lower 3D FID, MMD, and Wasserstein distance than HA-GAN, 3D LDM, and WDM-3D, but it does not expose one headline numeric score in the abstract. 6
- Code / resources: github.com/Fredy-Zhang/PRDiT. 6
LSM: semantic modulation for linear recurrent super-resolution
- Area tag: Vision restoration / image super-resolution.
- arXiv: 2606.19901; first submitted June 18. 7
- Authors / institutions: Mingyu Choi, Woo Kyoung Han, Sunghoon Im, and Kyong Hwan Jin; the HTML lists Korea University and DGIST. 17
- Peer-review status: Accepted to CVPR 2026 Findings. 7
- Core problem: Linear recurrent units are stable and efficient, but their static parameterization and single-scan behavior limit direct use on spatially varying 2D restoration tasks. 7
- Method highlights: LSM adds a semantic modulating unit that modulates LRU behavior, categorizes pixels by learned prototypes, and enhances features through a learned dictionary. 7
- Results / takeaway: The paper reports state-of-the-art super-resolution quality with computational complexity on par with existing methods; the abstract does not expose a single headline PSNR or SSIM figure. 7
- Code / resources: github.com/MingyuChoi-run/LSM. 17
ML methods, MoE reliability, and security
Toward calibrated mixture-of-experts under distribution shift
- Area tag: ML methods / calibration / MoE.
- arXiv: 2606.20544; first submitted June 18. 8
- Authors / institutions: Gina Wong, Drew Prinster, Suchi Saria, Rama Chellappa, and Anqi Liu; the fetched arXiv HTML does not expose affiliations. 18
- Peer-review status: ICML 2026 journal reference. 8
- Core problem: Expert-level calibration does not automatically imply aggregate calibration when a soft-routed MoE sees a shift in routing configurations. 18
- Method highlights: The paper proves hard-routed MoEs preserve calibration under a broad class of region reweightings, shows why soft-routed MoEs can fail, and proposes robust adversarial reweighting objectives for the aggregate predictor. 8
- Results / takeaway: Across image and text benchmarks, the authors report improved accuracy-calibration tradeoffs under artificial and natural shifts, often with little or no accuracy cost; the abstract does not surface one universal headline metric. 18
- Code / resources: No public code link was visible in the arXiv abstract page or the fetched HTML excerpt. 8
Smooth SMoE: discontinuities in sparse mixture-of-experts
- Area tag: ML theory / sparse MoE.
- arXiv: 2606.19036; first submitted June 17. 9
- Authors / institutions: Tho Tran Huu, Huu-Tuan Nguyen, Thien-Hai Nguyen, Nhat-Tri Ho, Viet-Hoang Tran, Tho Quan, and Tan Minh Nguyen; the fetched arXiv HTML does not expose affiliations. 19
- Peer-review status: ICML 2026 Spotlight. 9
- Core problem: Top-k expert selection makes sparse MoEs discontinuous near routing boundaries, so nearby inputs can activate different expert sets and produce different outputs. 9
- Method highlights: The paper classifies discontinuities by order, proves lower-order discontinuity sets dominate thickened boundary volume, models random perturbations as diffusion, and introduces smoothing near discontinuities. 19
- Results / takeaway: The useful researcher takeaway is diagnostic: if top-k MoE routing looks unstable, the first place to inspect is low-order switching boundaries, because the theory says they dominate the neighborhoods a perturbed input is likely to hit. 19
- Code / resources: github.com/thotranhuu99/Smooth_SMoE. 19
SWAAP: data poisoning for learned world models
- Area tag: RL / world models / security.
- arXiv: 2606.18697; first submitted June 17. 10
- Authors / institutions: Yibin Hu, Xiaolin Sun, and Zizhan Zheng; the HTML lists Tulane University’s Department of Computer Science. 20
- Peer-review status: Submitted to NeurIPS 2026, so this is a preprint rather than a confirmed acceptance. 10
- Core problem: World models are updated from collected experience, which creates a training-time attack surface that can corrupt downstream planning through poisoned transition targets. 10
- Method highlights: SWAAP first finds a harmful but stealthy target world model through first-order bilevel optimization, then realizes it by gradient-matched poisoning of a limited fraction of fine-tuning transitions. 10
- Results / takeaway: Across DMControl, MyoSuite, and MetaWorld-style continuous-control benchmarks, the authors report substantial performance degradation while evading non-adaptive residual, CUSUM, and TRIM-style defenses; this is a warning that world-model robustness needs data-level and dynamics-level defenses, not only policy monitoring. 20
- Code / resources: No public code link was visible in the arXiv abstract page or the fetched HTML excerpt. 10
Cross-paper signals to watch
Three themes stand out. First, agent infrastructure is moving from prompt-only reasoning toward executable interfaces: ToolPro moves the service side, and OmniAgent moves the perception loop. Second, multimodal systems are spending more design effort on token economics: UniAR compresses visual autoregressive prediction, while EventDrive and PRDiT ask what extra sensor or voxel detail is worth carrying. Third, MoE systems are getting reliability work at two levels: calibrated MoEs study probabilistic trust under shifts, while Smooth SMoE studies discontinuities created by sparse routing.
For a reader choosing what to open first: start with OmniAgent if you work on long-video agents, Multi-LCB if you evaluate code models, EventDrive if you care about driving or event sensors, and Smooth SMoE / Calibrated MoE if you are debugging MoE behavior under routing shift.
References
- 1arXiv:2606.20517
- 2arXiv:2606.19992
- 3arXiv:2606.19341
- 4arXiv:2606.18242
- 5arXiv:2606.18249
- 6arXiv:2606.20112
- 7arXiv:2606.19901
- 8arXiv:2606.20544
- 9arXiv:2606.19036
- 10arXiv:2606.18697
- 11Multi-LCB HTML
- 12ToolPro HTML
- 13OmniAgent HTML
- 14EventDrive HTML
- 15UniAR HTML
- 16PRDiT HTML
- 17LSM HTML
- 18Calibrated MoE HTML
- 19Smooth SMoE HTML
- 20SWAAP HTML
Add more perspectives or context around this Post.